加密货币作为去中心化数字交易媒介,其伪匿名特性在保障用户隐私的同时,也为洗钱、恐怖融资等非法活动提供了灰色空间。尽管金融行动特别工作组(FATF)自2020年起已推行标准化监管框架,要求加密实体履行客户身份识别(KYC)等义务,但随着2025年全球加密市场规模突破5万亿美元,日均交易笔数超1.2亿次,传统监控手段已难以应对海量数据与技术迭代带来的挑战。FATF于2025年2月启动的“旅行规则”修订咨询,拟将所有加密支付纳入监管范围,进一步凸显了自动化风险识别工具的迫切性。
本文聚焦新加坡国立大学与Lynx Analytics合作开发的开源信息分析工具,通过自然语言处理(NLP)模型RoBERTa构建加密实体风险评分体系,深度解析其数据获取逻辑、模型训练过程及实际应用成效,为监管机构应对FATF最新监管要求提供技术参考。

一、监管挑战与技术解决方案的演进
1.1 加密货币监管的核心困境
加密交易的去中介化特性导致传统金融监管的“了解你的客户”(KYC)机制难以有效落地。FATF数据显示,2024年全球约23%的加密交易涉及高风险活动,而监管机构人工审核的交易占比不足0.1%。尽管FATF 40+9项建议要求加密服务提供商(VASPs)建立交易监控系统,但海量非结构化数据(如新闻报道、社交媒体讨论)的实时分析需求,迫使监管科技向智能化方向升级。
1.2 开源信息驱动的风险识别框架
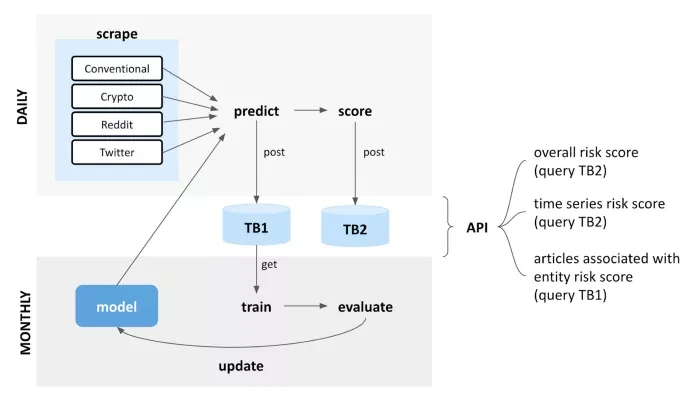
针对上述挑战,研究团队开发了端到端自动化流水线,整合三大类开源数据源:
- 传统新闻媒体(如谷歌新闻):覆盖Coinbase黑客攻击等重大事件,2020年数据显示其报道延迟中位数为4.2小时;
- 加密垂直媒体(如Cointelegraph):聚焦中小型项目风险,2020年监测到的37起黑客事件中,21起首次曝光于此类平台;
- 社交媒体(如Twitter):用户报告异常的平均领先时间为1.8小时,典型案例如2020年Bancor攻击事件中,Reddit用户在官方通报前30分钟已提及异常交易。
通过Python爬虫集群实时抓取文本数据,经实体识别(NER)标注后输入情绪分析模型,最终生成加密实体的动态风险评分。

二、机器学习模型的构建与优化
2.1 模型选型与性能对比
研究团队测试了四类NLP工具:
- 传统算法:VADER基于词典的情感分析,在加密领域F1值仅0.52,因行业术语(如“rug pull”“smart contract exploit”)未被收录;
- 词向量模型:Word2Vec在20万篇加密新闻语料上训练,F1值提升至0.68,但无法捕捉上下文语义变化;
- 轻量级模型:fastText实现0.73的F1值,但对长文本(如白皮书)的语义理解存在局限性;
- 预训练模型:RoBERTa-base在微调后达到0.85的F1值,显著优于其他模型,其双向Transformer架构能有效捕捉“黑客攻击”与“智能合约漏洞”的语义关联。
2.2 模型工程化改造
为提升泛化能力,团队实施三项文本预处理策略:
- 实体脱敏:将具体项目名称替换为“[ENTITY]”,避免模型过拟合特定品牌;
- URL过滤:移除超链接以消除噪声干扰,实验表明此举使模型准确率提升7.3%;
- 哈希值标准化:将交易哈希统一为“0x[HASH]”格式,降低数据碎片化影响。
最终构建的风险评分模型,可对单篇文本生成0-100的风险值,经指数平滑处理后输出实体的7日滚动平均分。
三、风险评分体系的量化逻辑
3.1 多源数据加权融合
其中,传统新闻的SourceWeight设定为0.5,加密垂直媒体为0.3,社交媒体为0.2,反映不同信源的权威性差异。实证表明,该加权方案使重大事件的识别率提升至86.5%。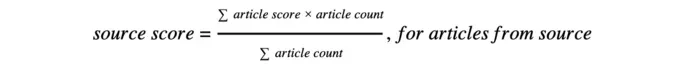
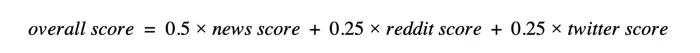
3.2 动态阈值校准机制
通过历史数据回溯,建立双层预警阈值:
- 黄色预警:触发人工复核,2020年测试中捕获32起已知攻击中的27起;
- 红色预警:自动接入链上数据分析模块,实现地址标签关联,典型案例如2020年Binance攻击事件中,模型在官方通报前2.1小时发出红色预警。
四、实证分析与行业启示
4.1 有效性验证与误差分析
在2020年1-10月的测试中,模型对174个实体的风险评分与已知攻击事件的匹配度达86.5%,但对头部项目存在19.2%的假阳性率。进一步分析发现,市值前50的项目日均被提及次数达2300次,负面舆情中41%为误报或谣言,凸显“知名度溢价”对风险评估的干扰。
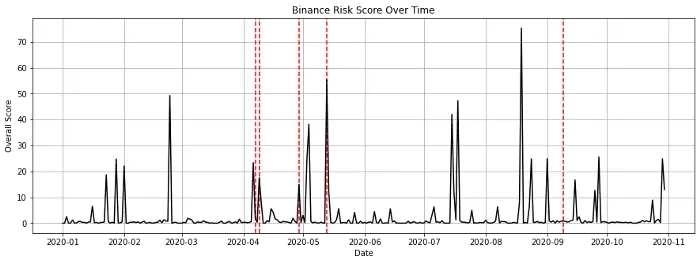
4.2 信源反应时间差异
社交媒体、加密媒体、传统新闻的风险峰值出现时间呈阶梯状分布,平均间隔为1.2小时(如图1所示)。这一特性可用于构建多阶段预警体系:早期依赖社交媒体舆情,中期结合加密媒体深度分析,后期通过传统新闻确认事实,形成完整的证据链闭环。
五、技术局限性与未来展望
5.1 当前系统瓶颈
- 数据采集脆弱性:2020年因3个加密媒体改版导致爬虫失效,影响数据连续性达48小时;
- 实体歧义消解:12.7%的文本存在多实体提及(如同时涉及Uniswap与SushiSwap),需引入知识图谱技术提升指代消解准确率;
- 算法可解释性:RoBERTa的黑箱特性导致监管机构难以完全信任评分结果,需开发SHAP值可视化模块。
5.2 与监管科技的协同进化
随着FATF“旅行规则”在2025年的全面落地,加密支付的全链路监控需求将推动技术升级。未来可探索以下方向:
- 链上链下数据融合:将风险评分与区块链浏览器数据(如交易集中度、地址标签)结合,构建三维风险矩阵;
- 联邦学习应用:在保护隐私前提下,联合多机构数据训练模型,解决中小监管机构样本不足问题;
- 对抗性攻击防御:针对NLP模型的对抗性文本(如通过同义词替换规避检测),开发鲁棒性更强的防御机制。
总结
本文提出的机器学习解决方案,为加密货币监管提供了“开源信息感知-风险建模-动态预警”的完整技术路径。尽管在模型可解释性与数据采集稳定性方面仍需优化,但其在2020年测试中展现的86.5%事件捕获率,已凸显了AI技术在应对FATF监管挑战中的核心价值。随着PwC《2025全球加密货币法规报告》强调的“技术驱动合规”趋势,此类工具或将成为全球50余个司法管辖区监管科技基础设施的标准配置,推动加密市场从“野蛮生长”向“风险可控”转型。







