在区块链世界里,数据就像散落在不同岛屿上的宝藏——每条链、每个协议都在生成海量信息,却被技术壁垒分割成一个个“数据孤岛”。对于DeFi开发者、分析师或资深用户来说,想要跨链获取完整的账户余额、交易历史或协议数据,往往需要对接多个接口、处理不同格式的原始数据,耗时又耗力。这正是Covalent试图解决的核心问题:它想成为那个连接所有岛屿的“数据桥梁”,让区块链数据从割裂走向统一。

从“数据孤岛”到“全链图景”
Covalent的定位很明确:不是简单的区块链浏览器,而是面向开发者的全链数据聚合平台。它通过爬取、索引并标准化来自以太坊、Polygon、Solana等70+条公链的原始数据,再通过统一的API接口提供给下游应用。这种“一站式”服务背后,藏着对区块链数据生态痛点的深刻理解——开发者不需要再为每条链单独开发数据抓取模块,用户也不用在多个工具间切换来拼凑完整的链上图景。
有意思的是,Covalent的技术路径选择了“广度优先”而非“深度定制”。它不像某些专注于特定公链的数据分析平台那样优化单一链的数据处理效率,而是追求覆盖尽可能多的区块链网络,甚至包括一些新兴的Layer2和小众公链。这种策略让它在多链时代抢占了先机——当DeFi协议开始跨链部署、用户资产分布在多条链上时,能提供“全链资产视图”的Covalent自然成了不少应用的首选数据层。
不只是“数据搬运工”,更是“价值提炼者”
如果仅仅是聚合数据,Covalent或许难以在竞争激烈的数据赛道脱颖而出。它的核心竞争力在于对原始数据的“二次加工”能力。通过自定义的索引规则和算法,Covalent能将区块链上的原始交易记录转化为结构化的“人类可读”数据。比如,它可以直接返回某个钱包在所有链上的NFT持仓清单,或某笔跨链交易在不同协议间的完整流转路径,这些都是开发者和用户真正需要的“高价值信息”。
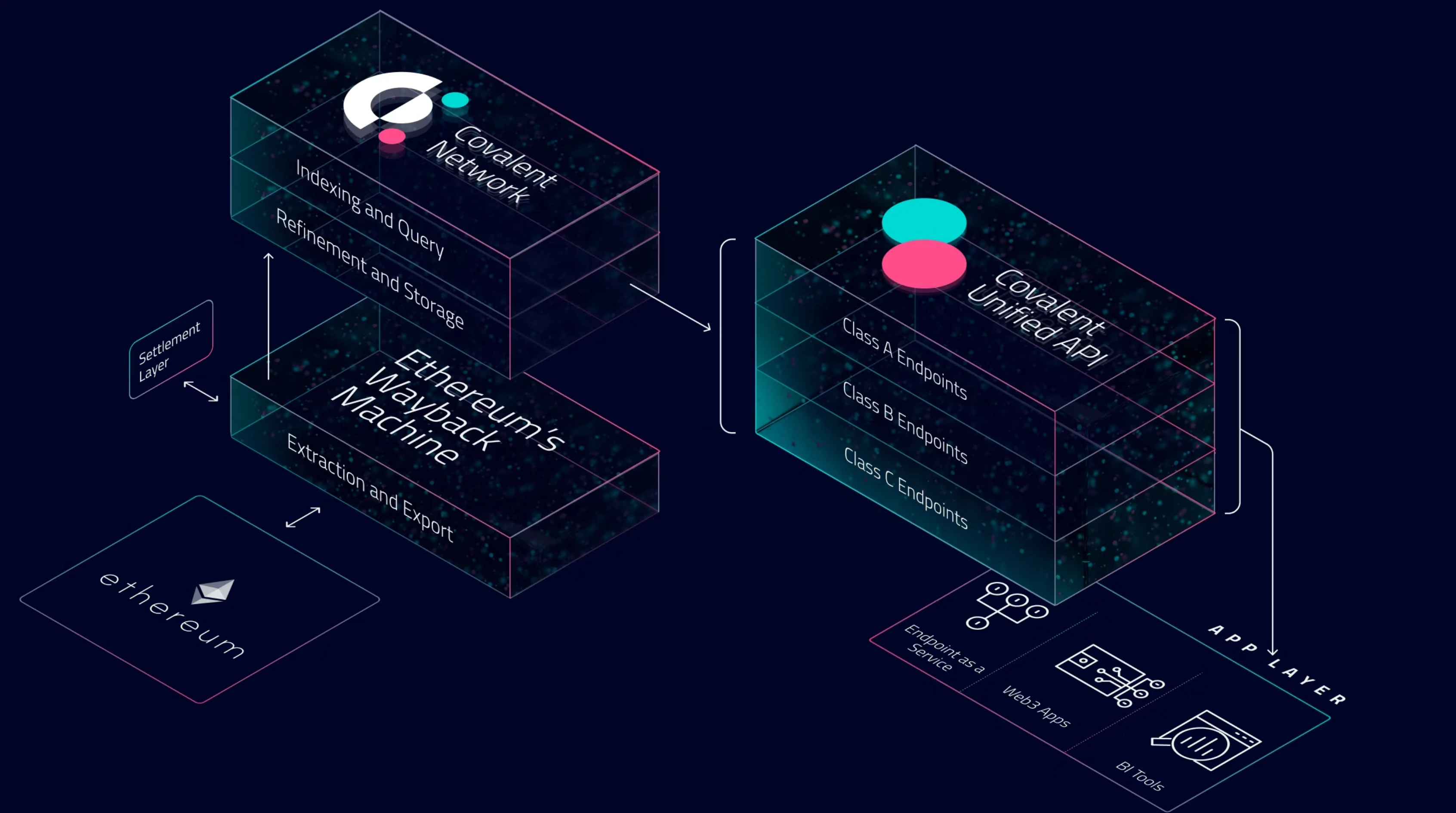
从实际应用来看,Covalent的触角已经延伸到DeFi的多个环节。Aave、SushiSwap等头部协议用它来展示用户的跨链抵押资产;链上分析工具Nansen通过其API补充长尾链数据;甚至一些Web3钱包也集成了Covalent的全链资产模块。这些案例印证了一个趋势:随着区块链应用复杂度提升,“数据中间层”的价值会越来越凸显,而Covalent正试图成为这个中间层的关键玩家。
光明与阴影:审慎乐观的现实考量
当然,数据聚合赛道从来不是一片蓝海。Covalent面临的挑战也很清晰:一方面,区块链数据的实时性和完整性始终是难题——当某条链出现拥堵或硬分叉时,数据同步延迟可能影响下游应用体验;另一方面,去中心化程度的平衡也考验着团队——目前Covalent的索引节点仍以中心化集群为主,虽然效率更高,但与区块链“去信任”的核心精神存在一定张力。
市场竞争同样不容忽视。The Graph作为去中心化数据索引协议,凭借其代币经济模型吸引了大量开发者;传统云计算厂商也开始布局区块链数据服务,试图用中心化技术优势挤压中间层生存空间。在这样的环境下,Covalent需要持续证明:它的“全链广度+标准化深度”组合,是不可替代的差异化优势。

写在最后
站在2025年的时间节点回望,Covalent的故事更像是区块链基础设施进化的一个缩影——从“能用”到“好用”,从“单一功能”到“生态协同”。它或许不是完美的解决方案,但确实为区块链数据的可访问性撕开了一道口子。对于加密行业进阶者而言,关注这类“默默做事”的基础设施项目,往往能更早捕捉到生态发展的底层逻辑。毕竟,在喧嚣的市场中,真正推动行业前进的,从来都是那些解决实际痛点的技术创新。



